
去年开始各大云厂商搞活动 120 元一年的云主机,当时还不会k8s,但是了解到搭建集群需要好几台,于是当时攒了好几台来做准备: tx 一台,阿里两个别人账号买了两台,再加上很久之前几何云送了一台. 当时还有人怼说买这么多干啥,答曰:以后学 k8s,此人曰:呵呵
后面刚开始接触的时候不太了解网络,用的calico,跨vpc根本不行,有大佬说只能vxlan能跨SDN下的vpc之间
但是云厂商的主机都是做的 ip 的nat,网卡ip都是内网ip,kubelet上报的时候和flannel都会用这个ip
- calico的 BGP 不能跨子网(好像需要人为干预配置才能跨)跨三层只能用ipip模式,另外个人网络知识不够,不懂BGP
- flannel 的 host-gateway 需要宿主机在同一个子网也就是说更不能跨 vpc,另外 host-gateway 我们这的 SDN 会对包进行过滤,如果机器的 ip 和 mac 绑定(默认)下发的包和发出去的网卡的 ip 和 mac 对不上会被 drop 掉,而且 host-gateway 需要每个主机的 docker0 不同网段,似乎搭建的话有点麻烦。flannel 的 vxlan 慢于 calico 的 ipip 模式, calico 的 ipip 不了解(另外ipip安全性不如 vxlan)
最开始 k8s 对网络设计提出一下要求
- 所有容器能够在没有 NAT 的情況下与其他容器通信。
- 所有节点能夠在没有 NAT 情況下与所有容器通信(反之亦然)。
- 容器看到的 IP 与其他人看到的 IP 是一样的。
于是每个 pod 都需要一个 ip,然后通过网络模型实现 pod,node,非本机 pod 之前通信,于是
- 高耦合的容器到容器通信(即一个pod内容器):通过 Pods 内 localhost 来通信。
- Pod 到 Pod 的通信:通过实现网络模型来解决。
- Pod 到 Service 通信:由 Service objects 结合 kube-proxy 解決。
- 外部到 Service 通信:一样由 Service objects 结合 kube-proxy 解決。
上面可以得出pod得有一个ip,但是又不得影响宿主机的原有网络,于是 svc 和 pod 的 ip 都是集群内的宿主机自嗨内网(人为干预可以让非集群机器访问到clusterip)
最首先的,master肯定是单个了,宣告的apiserver,也就是选项--advertise-address必须配置为master的公网IP,kubeadm的话是配置controlPlaneEndpoint,或者把一个指定域名加到 certSAN 里,用 hosts 代替
在flannel的vxlan模式里flannel.1充当了vxlan里的vtep身份,垮主机的pod通信流程可以简化到如下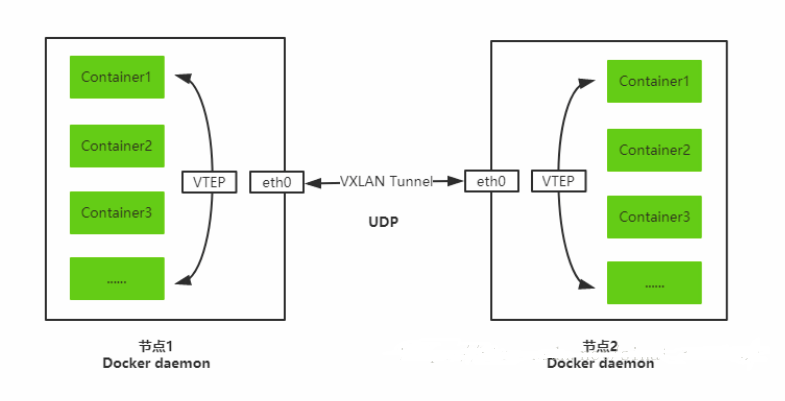
flannel查找到目标pod所在节点是通过查询etcd的node信息维护一张fdb表,可以通过下面命令查看。安装 iproute
1 | /usr/sbin/bridge fdb show dev flannel.1 |
kubelet上报的 ip 是主机的 eth0 的网卡ip,由于公有云 ecs 都是做的 ip 的 nat,上报的 ip 是内网 ip,各 vpc 里的主机向这个内网 ip 发包的话会在出公网后被运营商路由器 drop 掉(源目ip为内网ip不允许上公网)
最开始我从 calico 换成 flannel 的时候没注意目录/etc/cni/net.d/残留有 calico 的配置文件,导致 kubelet 还认为是跑的 calico,但是找不到 calico 一直报错,后面一气之下全部重装了操作系统
后面又搭建起来后发现(只有同一个node上的pod能互相访问)跨节点的 pod 之间无法通信,然后云上开了 flannel 的 udp 端口8472后依然不通。
测试 udp 端口通不通可以在 flannel 跑起来后安装 nc 命令测,发现几何云 udp 包会被 drop 掉,阿里、腾讯和百度的不会。
1 | echo -n foo | nc -4u -w1 <dest_public_ip> 8472 |
抓包则安装tcpdump抓
1 | tcpdump -nn port 8472 |
或者 nc 测试
1 | # server |
另外深信服的 超融合 和aCloud虚拟化平台会使用 8472/udp ,见文章 记一次K8S VXLAN Overlay网络8472端口冲突问题的排查。flannel需要修改端口,搜了下8475没分配
1 | $ kubectl -n kube-system edit cm kube-flannel-cfg |
最后找 flannel 的选项发现如下字段可以指定其他的 vtep 与自己通信的时候应该使用这个ip来通信
1 | [root@k8s-m1 ~]# docker run --rm quay.io/coreos/flannel:v0.10.0-amd64 --help |& grep -A1 public |
但是 flannel 的 pod 是 ds 跑的,如果每台机器都要配置各自的 public ip,可以通过改写initContainers的逻辑,通过类似curl ip.sb查询自己主机的公网出口ip来注入到一个变量里,然后工作容器的 ars 加上 -public-ip 即可
另一种是 flannel 官方 yaml 里有 RBAC 能够读取 node 的状态,kubectl describe node nodeName信息发现有Annotations如下
1 | Annotations: flannel.alpha.coreos.com/backend-data: {"VtepMAC":"xxxx"} |
看到这个命名public-ip可以十分肯定的知道改这里也能行了,于是如下命令修改完每个node信息为对应node的公网IP即可通信
1 | kubectl edit node <nodename> |
然后去对应node的8472端口抓包发现能通
后面发现kubectl exec和log命令是走的 node 的ip(也就是kubelet上报的各个主机的eth0的内网ip)会导致这俩命令超时
于是添加DNAT规则解决
1 | iptables -t nat -I OUTPUT -d 节点内网ip -j DNAT --to 节点的公网IP |
这里发现很小几率会出现做完上面的DNAT也不通和超时,我的某个node就出现这样情况,需要配合增加下面命令解决
1 | iptables -t nat -I POSTROUTING -o eth0 -s <目标节点内网ip> -j MASQUERADE |
然后测试pod的ip访问和svc的ip访问即可通信
一些flannel网络文章
http://yangjunsss.github.io/2018-07-21/%E5%AE%B9%E5%99%A8%E7%BD%91%E7%BB%9C-Flannel-%E4%B8%BB%E8%A6%81-Backend-%E5%9F%BA%E6%9C%AC%E5%8E%9F%E7%90%86%E5%92%8C%E9%AA%8C%E8%AF%81/
https://blog.51cto.com/14146751/2334560?source=dra
https://ieevee.com/tech/2017/08/12/k8s-flannel-src.html
https://programmer.ink/think/5da939768e5cb.html