
etcd 就不说了,奇数个副本,可以坏 (n-1)/2 个,但是不可能同时坏那么多,这里不讨论 etcd 单独不单独跑。推荐个文档 https://github.com/etcd-io/etcd/tree/master/Documentation/op-guide
管理组件
先说说 k8s 组件, kubelet 和 kube-proxy 啥的肯定写 LB 或者 VIP:HA_port,如官方的图
和 https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/ha-topology/ 里的,这里的文档内容有必要看一看的

下图是 etcd 不在 master 上的托盘拓扑

scheduler 和 controller 连接的 apiserver 地址我看网上有写 127 的也有写 LB 或者 VIP:HA_port 的,刚看到官方文档说两种都行 https://kubernetes.io/zh/docs/admin/high-availability/#%E8%BF%9B%E8%A1%8Cmaster%E9%80%89%E4%B8%BE%E7%9A%84%E7%BB%84%E4%BB%B6 ,这个文档已经被改没了,据我所了解到现在 2020 年 9 月这俩组件连 localhost 和 slb ip 都可以的
官方文档这说得基本有疑问的都写清楚了,前期 scheduler 和 controller 不支持 ha,后来增加了选举功能,他俩连 apiserver 的 ip 写 127.0.0.1 和负载均衡器都可以
apiserver
我们要明白的一点是 work 上 有cni(calico flannel …),kube-proxy,kubelet 这些都会连接 apiserver,通过向 apiserve 发 http 请求来反馈自身信息和同步要做的事情来保证 node 处于预期状态。
apiserver 本质上是个 web 七层服务,所以我们要整高可用不要把 k8s 想的太复杂了,保证了 apiserver 的高可用就行了。高可用实现的手段和工具看个人掌握的,例如上图官方的只说了 SLB,市面上也有其他的 local proxy 的实现方案。
流量入口单点的高可用
- 云上SLB
- 硬件LB
- 自己软件负载均衡,常见 nginx,haproxy,或者 keepalived+haproxy(基于VIP)
这三种高可用都是同一时间多台 apiserver 下,所有流向 apiserver 的流量是全部涌向 SLB/LB/VIP 上的,SLB 和 LB 稳定性高于 VIP,VIP 一般是 keepalived+haproxy 的方式,也就是所有流量同时流向拥有 VIP 的那台机器。硬件 LB 和 SLB 出故障了可以联系厂商,VIP 的 HA 最好是懂 keepalived+haproxy。不过一般的节点数量超过 20 台公司规模很大了,HA 方面肯定会有懂的人调优,也可以 ospf+lvs. 另外很多人不懂网络,云上用不了 VIP 的,一般都关闭了组播并且 openstack 存在网卡 ip 和 mac 的绑定关系(青云测试了没有绑定关系),见博客 https://zhangguanzhang.github.io/2018/07/18/ecs-vip/
阿里的 SLB 四层有个问题(snat模式)
client访问 SLB 流程
下面是 client 访问 SLB,没有问题
1 | +-------+ |
snat 下,client 访问 SLB 包从 client 出去未到 SLB 上,源目 IP 为
1 | src: clientIP dest: SLBIP |
SLB 做 SNAT 访问 rs:
1 | src: SLBIP dest: rsIP |
SLB 给 client 回包,把包里的源 IP 替换成自己的 ip
1 | src: SLBIP dest: clientIP |
客户端感知的是 SLB 回包
real server访问SLB流程(SNAT模式下的话)
apiserver 也会去访问 scheduler 和 controller,也就是下面这样,rs 访问 SLB,
1 | +-------+ |
SLB 是 snat 模式下,rs 访问 SLB,发出去的包源目 IP 为
1 | src: ownIP dest: SLBIP |
到了 SLB 上做了 snat 后
1 | src: SLBIP dest: SLBIP |
然后就环了,rs 收不到回包
kubeadm 的方案
根据官方的文档,kubeadm 的 HA 在 init 的时候执行配置就可以达到了,如下:
https://kubernetes.io/docs/setup/independent/high-availability/ 该文档也被修改没了,之前的内容是下面的
1 | apiVersion: kubeadm.k8s.io/v1beta1 |
controlPlaneEndpoint:为负载均衡器(SLB or 硬件LB)的地址或DNS + 端口
而这个 controlPlaneEndpoint 实际上最终会取 ip(注意不带端口)写到 kube-apiserver 的选项 --advertise-address 作为值。
默认情况下 --advertise-address 不配置下它的值将会和 --bind-address 一样。它的作用就是宣告,在 etcd 启动后 kube-apiserver 初次起来后会创建一个 svc 名叫kubernetes
1 | kubectl get svc kubernetes |
这个 svc 的 endpoints(ep) 就是选项 --advertise-address 的 ip ,port 则是 apiserver 的--secure-port。假设用户配置的--secure-port为 6443 ,所以一般云上 SLB 的话那这个宣告可以填写 LB 的 ip,然后默认的 kubernetes 的 endpoints 是 <SLB_IP>:6443。
1 | kubectl describe ep kubernetes |
vip 单点的坑之 –advertise-address
截止到现在似乎都没有啥坑,但是这几天写生产环境的部署方案的时候,因为考虑到多网卡,而 kubeadm 部署的默认很多组件是 bind 0.0.0.0 的会导致所有网卡的ip的请求都会监听。
我测试的机器 ip 信息为
| IP | Hostname | CPU | Memory |
|---|---|---|---|
| 172.16.1.2 | k8s-m1 | 4 | 8G |
| 172.16.1.3 | k8s-m2 | 4 | 8G |
| 172.16.1.4 | k8s-m3 | 4 | 8G |
于是我--bind-address写网卡 ip 例如三台分别是 172.16.1.2、3、4, HA 用的 keepalived+haproxy , vip 是5。因为 master 上 6443 被 apiserver 监听了,所以 haproxy 是另一个端口我是用的 8443。
而坑就是宣告,我仿照官方意见--advertise-address写了VIP(带不了端口,否则报错)。启动了 apiserver 后默认宣告 kubernetes 的 ep 是 VIP:6443,
1 | kubectl describe ep kubernetes |
发现后面例如 flannel 的 pod 要请求 apiserver 的时候走它根本不通。因为 apiserver 是 bind 的单张网卡 ip,而 haproxy 是 bind 0.0.0.0:8443,没有任何进程是 bind vip:6443。
1 | netstat -nlpt |
这里并没有0.0.0.0:6443的 bind,所以请求走 vip:6443 是不通的。
于是我 patch 了 ep 改为了 8443。但是后面发现只要一重启 kube-apiserver 就宣告的 ep 的 port 就成了 6443。
之前 apiserver 是 bind 0.0.0.0 是没问题的,所以如果是多网卡还用的 VIP 这种 ha下,宣告还是写 node 自己的网卡ip或者不写。
写 node 的网卡 ip 测试
写 node 的网卡 ip 后,apiserver 存活期间会去更新 ep 的 ttl,只要 apiserver 宕了它的 ep 会因为没有刷新 ttl 而被自动剔除。这个想法是 issue 里看到别人提到的想法,也就是现在的工作原理。
下面测试是在 1.13.5 上测试的,在 m3 上停掉 apiserver
1 | [root@k8s-m3 ~]# systemctl stop kube-apiserver |
在 m3 上启动 apiserver
1 | [root@k8s-m3 ~]# systemctl restart kube-apiserver |
我们先来看下这 ep 相关的选项
1 | kube-apiserver --help | grep -- endpoint-reconciler-type |
根据代码 https://github.com/kubernetes/kubernetes/blob/v1.10.1/cmd/kube-apiserver/app/options/options.go#L97 可以知道 1.10 以及之前是 master-count 的形式
1 | EndpointReconcilerType: string(reconcilers.MasterCountReconcilerType) |
而1.11 https://github.com/kubernetes/kubernetes/blob/v1.11.1/cmd/kube-apiserver/app/options/options.go#L96 开始则是默认使用 lease
这俩区别看代码
https://github.com/kubernetes/kubernetes/blob/97a4e6683e6250c0bc198cd4f3bdb501ccadfdaf/pkg/master/master.go#L229-L264
https://github.com/kubernetes/kubernetes/blob/master/pkg/master/reconcilers/lease.go#L146
https://github.com/kubernetes/kubernetes/blob/master/pkg/master/reconcilers/mastercount.go#L62
查阅代码可知,master-count 是每个 apiserver 去用endpointsAdapter 去把自己的 ip 作为 endpoint 打到svc kubernetes上,而 lease 则是写 etcd 的存储,然后根据 etcd 去更新 ep
1 | etcd_v3 get --prefix /registry/masterlease --keys-only |
所以 1.11 开始默认我们不需要去配置--apiserver-count
其他实现手段
软件实现方案不仅仅是 keepalived+haproxy,还有其他的例如 nginx,envoy 都能做到,HA 是思想而不是依赖于具体的软件工具
Local Proxy
前面的都是流量从 node 出去的后全部涌向 HA 的点上,然后再分散调度到所有的 apiserver 上,如果一开始从 node上分散开来呢。例如第一次向 apiserver 发起请求是发到第一个 rs 上,第二次请求是发到第二个 rs 上。
worker 节点相关的组件都是只能写一个 ip 地址,所以我们可以定一个 VIP(虚拟IP),流量发到 VIP,vip 在 node 自己上,然后 rs 就是 apiserver,从起点就开始分散开了。市面上比较火的一个 sealos 就是魔改了 kubeadm,staticPod 的目录加了个 yaml,使用的四层 lvs 做负载。每个 node 跑一个 lvs 的 watch 进程 pod 去维护 lvs 的规则保持高可用: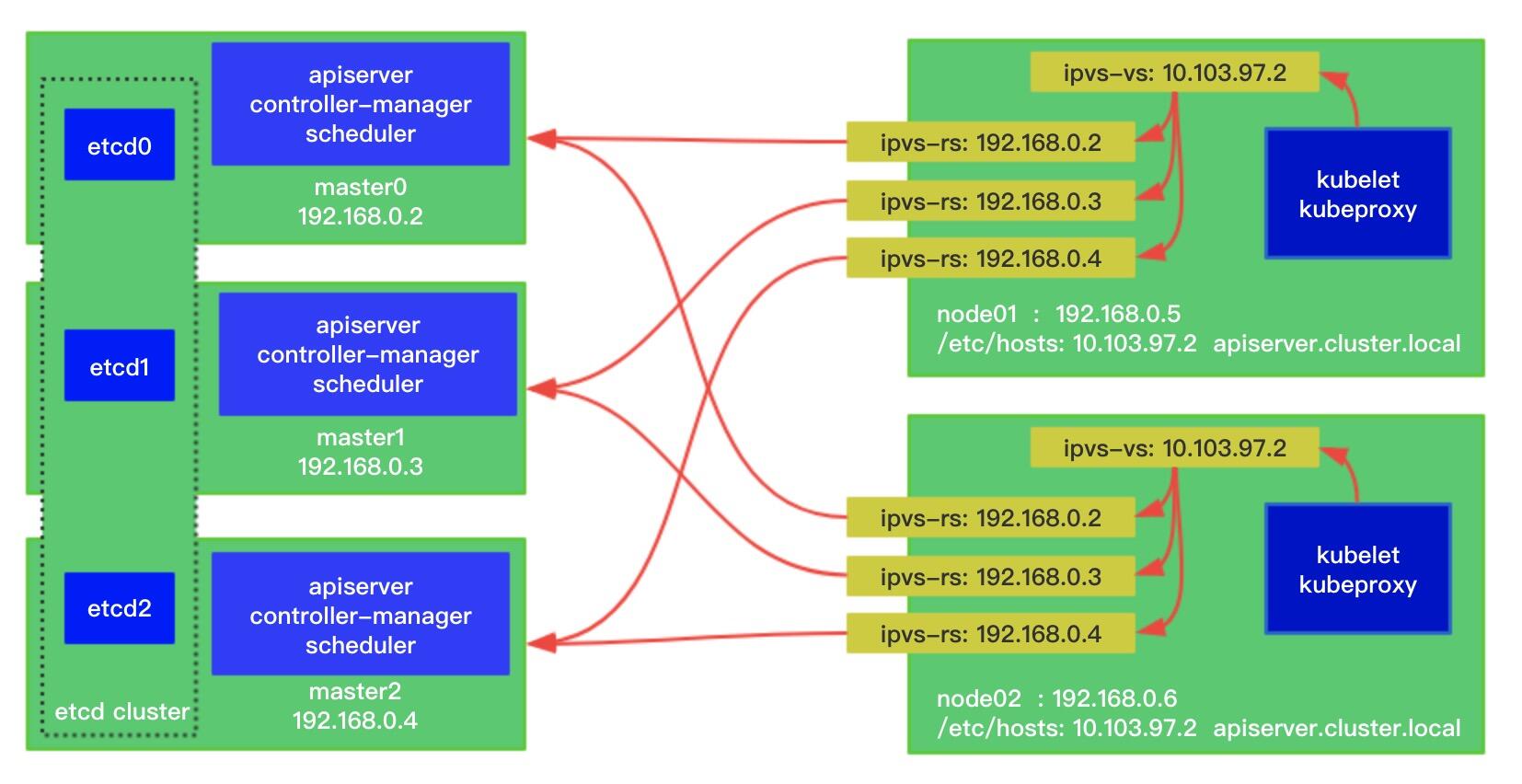
这里不单单是 sealos 实现,我们自己用 nginx 和 haproxy 以及 envoy 都能实现,主要是思想。同时 local proxy 这种是不依赖外部负载均衡的,并且在云上限制较多的地方,以及私有化各种复杂场景,local proxy 一劳永逸。
混合
例如下面,单独的两个 LB 的 machine 上,然后 proxy 到 apiserver 上, vip 也可以 lvs 直接分别调度到 L1 或者 L2 上,然后再 proxy 到 apiserver
1 | proxy +-------+ |
一些其他的
如果说有的云 SLB 不像阿里的那样,可以配置 kube-apiserver 的思路为:四层负载模式,健康检查是七层去 get apiserver 的 web 路由/healthz,不过这个路由是需要鉴权的,我们可以关闭鉴权
1 | kubectl apply -f https://raw.githubusercontent.com/zhangguanzhang/Kubernetes-ansible-base/roles/master/files/healthz-rbac.yml |