
这个问题 flannel 和 calico 的 VXLAN 模式下都会发生,部分人的现象是集群的A记录 UDP 下查询可能有问题(也有人在 azure 上在宿主机上访问 svc 的 clusterIP 10%几率才能通),原因是v1.17+的k8s会引起内核的某个 UDP 相关 bug而不是cni的软件层面,weave没有,后面说。
写这篇文章的日期是05/28,发现是上周五也就是05/23号,文章从时间线写起(因为很多时候想发文章但是没空,所以文章的发布日期是05/23)
2020-07-19更新,版本v1.18.6, v1.16.13, v1.17.9+已经修复这个问题,可以同版本内升级,或者只切kube-proxy版本
由来
上周五我经过同事的工位看到同事的桌面是k8s的get po的输出,问他咋开始学k8s了,他说跟着视频学下,看了下用的kubeadm部署了一套1.18.2的集群。1.18的kube-proxy的ipvs包的parseIP有bug,我推荐他换v1.17.5。他当时在部署一个入门的svc实验,换了后还是无法解析域名(实际上后面对照组v1.18.2也解析不了)。使用dig命令排查了下,下面是对照:
dig @<podIP> +short kubernetes.default.svc.cluster.local能解析dig @10.96.0.10 +short kubernetes.default.svc.cluster.local超时
很多市面上的kubeadm部署教程都是直接kubeadm init,所以我推荐同事去按照我文章的kubeadm部署一套后再试试,叫他用v1.17的最新版本v1.17.5,结果还是上面一样。coredns实际上还有metrics的http接口,从http层测了下:
curl -I 10.96.0.10:9153/metrics超时,很久之后才有返回curl -I <podIP>:9153/metrics能直接返回
涉及到本次排查的信息为
1 | $ kubectl get node -o wide |
多次尝试发现很久的时间都是一样,用time命令观察了下一直是63秒返回。包括其他任何svc都是这样
1 | $ time curl -I 10.96.0.10:9153/metrics |
proxyMode是ipvs,用ipvsadm看下超时的时候的状态,一直是SYN_RECV,也就是发送了SYN,没收到回包
1 | # ipvsadm -lnc |& grep 9153 |
抓包
因为cni使用的flannel,用的vxlan模式。master上抓9153和flannel.1的8472端口,coredns的pod所在node上抓flannel的vxlan包,下面三个是对应的:
1 | [root@master /root]# tcpdump -nn -i flannel.1 port 9153 |
1 | [root@master /root]# tcpdump -nn -i eth0 port 8472 |
1 | [root@node2 /root]# tcpdump -nn -i eth0 port 8472 |
先看上面的第一部分,搜了下资料 https://blog.csdn.net/u010039418/article/details/78234570
得知tcp默认SYN报文最大retry 5次,每次超时了翻倍,1s -> 3s -> 7s -> 15s -> 31s -> 63s。只有63秒的时候node的机器上才收到了vxlan的报文。说明pod所在node压根没收到63秒之前的。
一般lvs的dr模式下tcp的时间戳混乱或者其他几个arp的内核参数不对下SYN是一直收不到的而不是63秒后有结果,所以和内核相关参数无关。于是同样上面的步骤tcpdump抓包,加上-w选项把抓的包导出下来导入到wireshark里准备看看
报文分析
9153的包wireshark里看63秒前面都是tcp的SYN重传,看到了master上向外发送的vxlan报文的时候有了发现。下面的截图是放github上的,网络不好会看不到截图
可以看到udp的checksum是0xffff,我对udp报文不太熟悉,udp的header的checksum没记错的话crc32校验的,不可能是这种两个字节都置1的0xffff,明显就是udp的header的校验出错了。后面几个正常包的checksum都是missing的
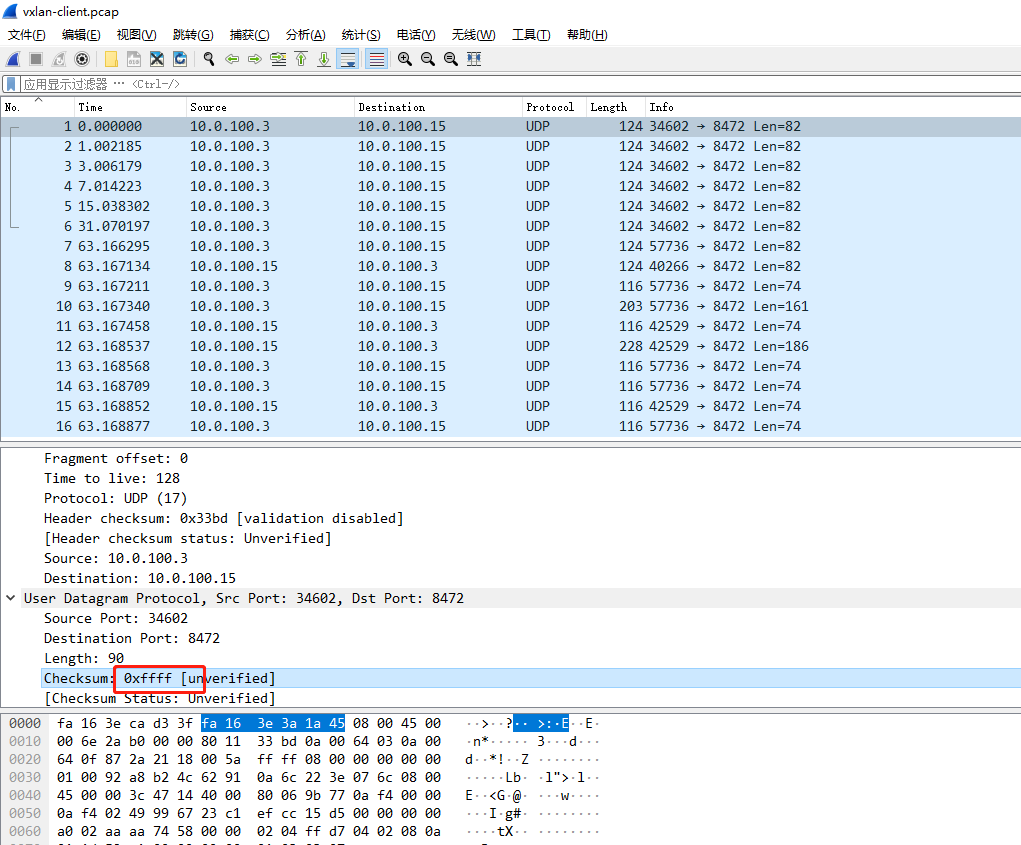
wireshark的编辑->首选项->Protocols->UDP的Validate the UDP checksum if possible勾上更直观看
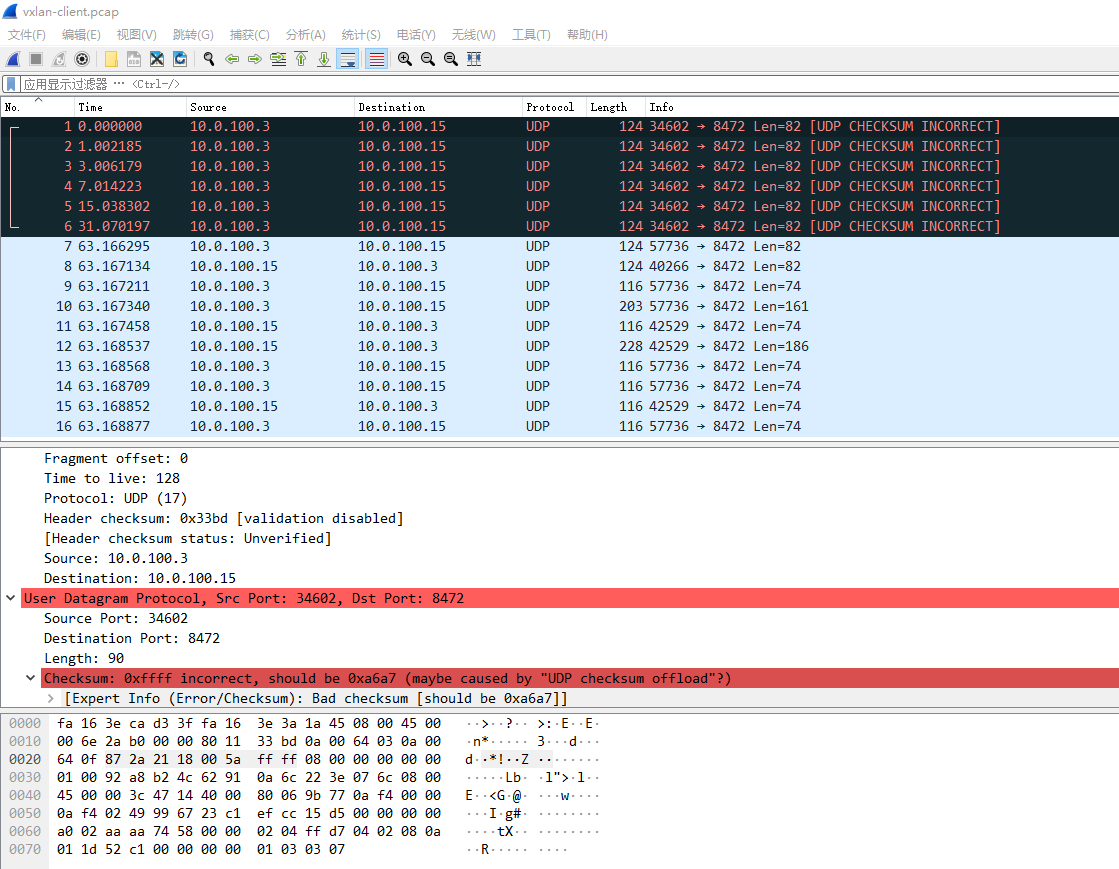
解决
搜了下wireshark linux udp checksum incorrect,都是推荐把checksum offload disable掉就行了,例如我这里是flannel,则是
1 | $ /sbin/ethtool -K flannel.1 tx-checksum-ip-generic off |
再测下正常,而weave他们也用的vxlan模式,但是他们在创建网卡的时候把这个已经off掉了,所以他的vxlan模式在v1.17+集群没出现这个问题
1 | $ time curl -I 10.96.0.10:9153 |
你以为这样就完了?其实并没有,因为我自己维护了一套ansible部署k8s的方案,每次新版本发布我都会实际测下。并且同事反映了他同样云主机开出来用我ansible部署v1.17.5没有这个问题。这就很奇怪了,原因后面说,请接着继续看
什么是checksum offload
资料:
- https://wiki.wireshark.org/CaptureSetup/Offloading
- https://zh.wikipedia.org/wiki/TCP%E6%A0%A1%E9%AA%8C%E5%92%8C%E5%8D%B8%E8%BD%BD
- Checksum Offload 是网卡的一个功能选项。如果该选项开启,则网卡会负责计算需要发送或者接收到的TCP消息的校验和,从而节省CPU的计算开销。此时,在需要发送的消息到达网卡前,系统会在TCP报头的校验和字段填充一个随机值。
但是,尽管Checksum Offload能够降低 CPU 的计算开销,但受到计算能力的限制,某些环境下的一些网卡计算速度不如主频超过400MHz的CPU快
正文
对照组
很奇怪的就是为啥就是我的ansible部署的二进制就正常没这个问题,而kubeadm部署的就不正常,后面我花时间整了以下几个对照组(期间同事也帮我做了几个条件下的测试,但是不是系统用错了就是版本整错了。。。),终于找到了问题的范围,下面是我自己统计的对照组信息,kubeadm和ansible版本均为1.17.5测试。os不重要,因为最终排查出和os无关
| os | type(kubeadm or ansible) | flannel version | flannel is running in pod? | will 63 sec |
|---|---|---|---|---|
| 7.6 | kubeadm | v0.11.0 | yes | yes |
| 7.6 | kubeadm | v0.12.0 | yes | yes |
| 7.6 | kubeadm | v0.11.0 | no | yes |
| 7.6 | kubeadm | v0.12.0 | no | yes |
| 7.6 | ansible | v0.11.0 | yes | no |
| 7.6 | ansible | v0.12.0 | yes | no |
| 7.6 | ansible | v0.11.0 | no | no |
| 7.6 | ansible | v0.12.0 | no | no |
这就看起来很迷了。但是排查出和flannel无关,感觉kube-proxy有关系,然后今天05/28针对kube-proxy做了个对照组
| os | type(kubeadm or ansible) | kube-proxy version | kube-proxy is running in pod? | will 63 sec |
|---|---|---|---|---|
| 7.6 | kubeadm | v1.17.5 | yes | yes |
| 7.6 | kubeadm | v1.17.5 | no | no |
| 7.6 | kubeadm | v1.16.9 | yes | no |
| 7.6 | kubeadm | v1.16.9 | no | no |
| 7.6 | ansible | v1.17.5 | yes | yes |
| 7.6 | ansible | v1.17.5 | no | no |
可以看出就是1.17以上的版本如果使用pod则会有这个问题,而非pod则不会,github上compare了下v1.17.0和v1.16.3 https://github.com/kubernetes/kubernetes/compare/v1.16.3...v1.17.0
发现了Dockerfile的改动 https://github.com/kubernetes/kubernetes/commit/fed582333f639dc22e879f4bbb258e403c210c30
见上面的commit 1.17.0里的 Dockerfile 的BASEIMAGE是用 指定了一个源安装了最新的iptables,然后利用update-alternatives把脚本/usr/sbin/iptables-wrapper去替代iptables 来检测应该使用nft还是legacy, hack 下镜像回自带源里的 iptables 验证下
1 | FROM registry.aliyuncs.com/google_containers/kube-proxy:v1.17.5 |
构建的镜像推送到了dockerhub上zhangguanzhang/hack-kube-proxy:v1.17.5,更改下集群kube-proxy ds的镜像
1 | $ kubectl -n kube-system get ds kube-proxy -o yaml | grep image: |
测试访问成功
1 | time curl -I 10.96.0.10:9153 |
对于这个问题我在flannel的pr下面也参与了回复,https://github.com/coreos/flannel/pull/1282 官方github上提了一个issue https://github.com/kubernetes/kubernetes/issues/91519
这个问题的触发是由于v1.17+的 kube-proxy 的 docker 镜像里安装了最新的 iptables , --random-fully选项会触发内核vxlan的bug
总结
解决问题三种办法:
- 关闭vxlan的网卡的checksum offload
- 更改Docker镜像
- 升级到新内核,具体版本就不知道了,只要在这个内核pr并后出的内核版本都行 https://github.com/torvalds/linux/commit/ea64d8d6c675c0bb712689b13810301de9d8f77a