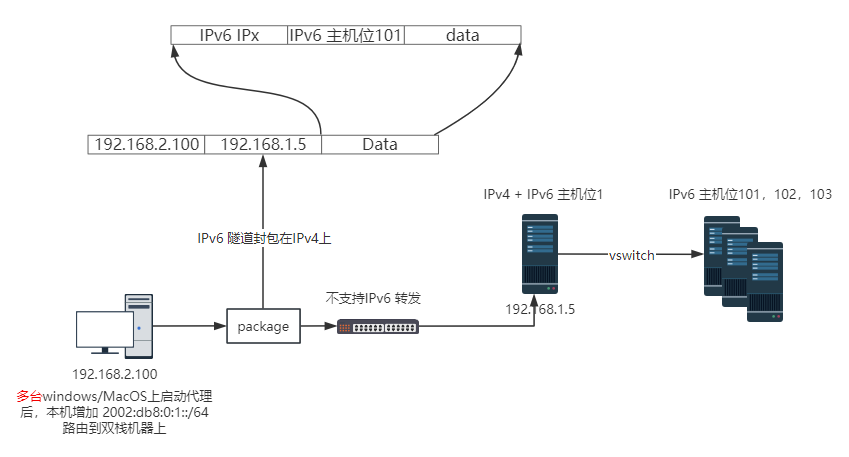
auto eth0 allow-hotplug eth0 iface eth0 inet dhcp up ip -6 route add default via fe80::ecff:ffff:feff:ffff dev eth0 up ip -6 route add 2401:xxxx:xxx:xxxx::/64 dev eth0
kubelet_node_status.go:92] "Unable to register node with API server" err="Node \"2002.db8.0.1..101\" is invalid: metadata.name: Invalid value: \"2002.db8.0.1..101\": a lowercase RFC 1123 subdomain must consist of lower case alphanumeric characters, '-' or '.', and must start and end with an alphanumeric character (e.g. 'example.com', regex used for validation is '[a-z0-9]([-a-z0-9]*[a-z0-9])?(\\.[a-z0-9]([-a-z0-9]*[a-z0-9])?)*')" node="2002.db8.0.1..101"
err="error creating bootstrap controller: service IP family \"2001:cafe:43::/112\" must match public address family \"10.x.x.x\""
原因是我根据源码里搜 must match public address family 找到如下逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// cmd/kube-apiserver/app/options/validation.go funcvalidatePublicIPServiceClusterIPRangeIPFamilies(extra Extra, generic genericoptions.ServerRunOptions) []error { // The "kubernetes.default" Service is SingleStack based on the configured ServiceIPRange. // If the bootstrap controller reconcile the kubernetes.default Service and Endpoints, it must // guarantee that the Service ClusterIPRepairConfig and the associated Endpoints have the same IP family, or // it will not work for clients because of the IP family mismatch. // TODO: revisit for dual-stack https://github.com/kubernetes/enhancements/issues/2438 if reconcilers.Type(extra.EndpointReconcilerType) != reconcilers.NoneEndpointReconcilerType { serviceIPRange, _, err := controlplaneapiserver.ServiceIPRange(extra.PrimaryServiceClusterIPRange) if err != nil { return []error{fmt.Errorf("error determining service IP ranges: %w", err)} } if netutils.IsIPv4CIDR(&serviceIPRange) != netutils.IsIPv4(generic.AdvertiseAddress) { return []error{fmt.Errorf("service IP family %q must match public address family %q", extra.PrimaryServiceClusterIPRange.String(), generic.AdvertiseAddress.String())} } }
returnnil }
flannel
最终部署完发现 flannel 报错:
1 2 3 4 5 6 7 8 9 10 11 12
vxlan_network.go:265] failed to add v6 vxlanRoute (2002:db8:42:2::/64 -> 2002:db8:42:2::): All attempts fail: #1: no route to host #2: no route to host
retry.go:29] #0: no route to host retry.go:29] #1: no route to host retry.go:29] #2: no route to host
# 路由信息 # ip -6 r s | grep flannel 2001:cafe:42:: dev flannel-v6.1 proto kernel metric 256 pref medium fe80::/64 dev flannel-v6.1 proto kernel metric 256 pref medium
最终在官方仓库文档找到说明:
1 2
# https://github.com/flannel-io/flannel/blob/master/Documentation/configuration.md#dual-stack vxlan support ipv6 tunnel require kernel version >= 3.12
$ ip addr add ee80:169:254::1/128 dev lo $ ip addr add fe80:169:254::1/128 dev lo $ go run main.go ee80:169:254::1 Listening on [ee80:169:254::1]:8080 ^Csignal: interrupt $ go run main.go fe80:169:254::1 Error listening: listen tcp6 [fe80:169:254::1]:8080: bind: invalid argument [root@guan ~/test/gotest]# uname -a Linux guan 5.4.0-182-generic #202-Ubuntu SMP Fri Apr 26 12:29:36 UTC 2024 x86_64 x86_64 x86_64 GNU/Linux [root@guan ~/test/gotest]# ip -6 a s lo 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 inet6 ee80:169:254::1/128 scope global valid_lft forever preferred_lft forever inet6 fe80:169:254::1/128 scope link valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever
// Open a UDP connection to determine which external IP address is // used to access the supplied destination. protocol := "udp6" if dest[0] != '[' { dest = fmt.Sprintf("[%s]", dest) } address := fmt.Sprintf("%s:80", dest) conn, err := net.Dial(protocol, address) if err != nil { return"", err } defer conn.Close() // nolint: errcheck
// Get the local address as a golang IP and use that to find the matching // interface CIDR. addr := conn.LocalAddr() if addr == nil { return"", fmt.Errorf("no address detected by connecting to %s", dest) } udpAddr := addr.(*net.UDPAddr)
// Get a full list of interface and IPs and find the CIDR matching the // found IP. netIfaces, err := net.Interfaces() if err != nil { return"", err } for _, iface := range netIfaces { netAddrs, err := iface.Addrs() if err != nil { return"", err }
for _, netAddr := range netAddrs { ifNet, _, _ := net.ParseCIDR(netAddr.String()) if udpAddr.IP.Equal(ifNet) { return iface.Name, nil }
} }
return"", fmt.Errorf("autodetected IPv6 address does not match any addresses found on local interfaces: %s", udpAddr.IP.String()) }
funcsplitByLastColon(s string) (string, string) { // Find the last occurrence of ":" index := strings.LastIndex(s, ":") if index == -1 { // No colon found, return the whole string as the first part return s, "" } // Split the string into two parts part1 := s[:index] part2 := s[index+1:] return part1, part2 }
funcReachDestinationInterfaceName(dest string, version int) (string, error) {
// Open a UDP connection to determine which external IP address is // used to access the supplied destination. protocol := fmt.Sprintf("udp%d", version) if dest[0] != '[' { dest = fmt.Sprintf("[%s]", dest) } address := fmt.Sprintf("%s:80", dest) conn, err := net.Dial(protocol, address) if err != nil { return"", err } defer conn.Close() // nolint: errcheck
// Get the local address as a golang IP and use that to find the matching // interface CIDR. addr := conn.LocalAddr() if addr == nil { return"", fmt.Errorf("no address detected by connecting to %s", dest) } udpAddr := addr.(*net.UDPAddr)
// Get a full list of interface and IPs and find the CIDR matching the // found IP. netIfaces, err := net.Interfaces() if err != nil { return"", err } for _, iface := range netIfaces { netAddrs, err := iface.Addrs() if err != nil { return"", err }
for _, netAddr := range netAddrs { ifNet, _, _ := net.ParseCIDR(netAddr.String()) if udpAddr.IP.Equal(ifNet) { return iface.Name, nil }
} }
return"", fmt.Errorf("autodetected IPv%d address does not match any addresses found on local interfaces: %s", version, udpAddr.IP.String()) }
$./reach 223.5.5.5 interface:ens18 localIP:192.168.2.112 $ ./ ip a s ens18 2: ens18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 7e:bf:9c:27:f5:9e brd ff:ff:ff:ff:ff:ff inet 192.168.2.112/24 brd 192.168.2.255 scope global ens18 valid_lft forever preferred_lft forever inet6 fe80::7cbf:9cff:fe27:f59e/64 scope link valid_lft forever preferred_lft forever
$ ./reach 2408:8656:22df:ff01::13:111 interface:ens160 localIP:2408:8656:22df:ff01::13:181 $ ip a s ens160 2: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 00:50:56:a0:df:2e brd ff:ff:ff:ff:ff:ff inet6 2408:8656:22df:ff01::13:181/119 scope global valid_lft forever preferred_lft forever inet6 fe80::250:56ff:fea0:df2e/64 scope link valid_lft forever preferred_lft forever
# these flags will be used by RabbitMQ nodes RABBITMQ_SERVER_ADDITIONAL_ERL_ARGS="-kernel inetrc '/etc/rabbitmq/erl_inetrc' -proto_dist inet6_tcp" # these flags will be used by CLI tools RABBITMQ_CTL_ERL_ARGS="-proto_dist inet6_tcp"
第二天他在 Linux 上发现相关问题,开了猫咪代理后内嵌页有内容,问他是不是猫咪自动更新了,给我截图了下界面,看了下 IPv6 选项开启的,让他关闭后再试试就不行了,而 windows 上猫咪开不开 IPv6 选项都不行。 发现很奇怪,就要来了安装包,自己开了个 windows 也复现这个了问题,想着看了下猫咪 meta 内核源码能不能找到眉目, yaml ipv6 字段使用的地方:
1 2 3 4 5 6
type General struct { Inbound Mode T.TunnelMode `json:"mode"` UnifiedDelay bool`json:"unified-delay"` LogLevel log.LogLevel `json:"log-level"` IPv6 bool`json:"ipv6"`
然后传递配置变量里
1 2 3
if general.IPv6 != nil { resolver.DisableIPv6 = !*general.IPv6 }
解析行为相关的函数
1 2 3 4 5 6 7 8 9 10 11 12 13
funcLookupIPWithResolver(ctx context.Context, host string, r Resolver) ([]netip.Addr, error) { if node, ok := DefaultHosts.Search(host, false); ok { return node.IPs, nil }
if r != nil && r.Invalid() { if DisableIPv6 { return r.LookupIPv4(ctx, host) } return r.LookupIP(ctx, host) } elseif DisableIPv6 { return LookupIPv4WithResolver(ctx, host, r) }
该域名 A 记录和 AAAA 记录都有,设置下测试 windows 的 dns server 指向双栈机器点了下登录后,发现 coredns 日志里解析的是 A 记录解析请求,问题就是这了,A 记录的 IP 机器上抓包发现 http GET 请求发过来了,但是机器没有监听这个端口,所以内嵌登录页还是空白内容。