记录下 docker k8s 使用 gpu 的笔记
由来 网上 nvidia-container-toolkit 一些文档的时效性,而且主要是私有化、离线和小白角度下的笔记
安装 nvidia GPU 驱动 这个文章 nvidia-gpu-operator-simplifying-gpu-management-in-kubernetes 有说使用 nvidia gpu operator 来部署,不需要在宿主机上安装驱动,但是看文档 supported-nvidia-data-center-gpus-and-systems 没有 RTX 4090 支持。所以大家常规都是使用 nvidia-container-toolkit 方案的 官方文档 的结构:
对于 NVIDIA GPU Operator 感兴趣直接看 NVIDIA GPU Operator 官方文档
系统前置配置 推荐 ubuntu 22.04 部署,具体支持的系统看 官方文档 supported-platforms 先确认系统层面识别到显卡:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 $ lspci | grep -i nvidia 1b:00.0 VGA compatible controller: NVIDIA Corporation Device 2684 (rev a1) 1b:00.1 Audio device: NVIDIA Corporation Device 22ba (rev a1) 1e:00.0 VGA compatible controller: NVIDIA Corporation Device 2684 (rev a1) 1e:00.1 Audio device: NVIDIA Corporation Device 22ba (rev a1) 22:00.0 VGA compatible controller: NVIDIA Corporation Device 2684 (rev a1) 22:00.1 Audio device: NVIDIA Corporation Device 22ba (rev a1) 23:00.0 VGA compatible controller: NVIDIA Corporation Device 2684 (rev a1) 23:00.1 Audio device: NVIDIA Corporation Device 22ba (rev a1) 4f:00.0 VGA compatible controller: NVIDIA Corporation Device 2684 (rev a1) 4f:00.1 Audio device: NVIDIA Corporation Device 22ba (rev a1) 52:00.0 VGA compatible controller: NVIDIA Corporation Device 2684 (rev a1) 52:00.1 Audio device: NVIDIA Corporation Device 22ba (rev a1) 56:00.0 VGA compatible controller: NVIDIA Corporation Device 2684 (rev a1) 56:00.1 Audio device: NVIDIA Corporation Device 22ba (rev a1) 57:00.0 VGA compatible controller: NVIDIA Corporation Device 2684 (rev a1) 57:00.1 Audio device: NVIDIA Corporation Device 22ba (rev a1)
查看 2684 可以进入 PCI Devices 下面输入 2684 点击 jump 会显示对应的卡名。或者让 lspci 的信息更新:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 $ update-pciids $ lspci | grep -i nvidia 1b:00.0 VGA compatible controller: NVIDIA Corporation AD102 [GeForce RTX 4090] (rev a1) 1b:00.1 Audio device: NVIDIA Corporation AD102 High Definition Audio Controller (rev a1) 1e:00.0 VGA compatible controller: NVIDIA Corporation AD102 [GeForce RTX 4090] (rev a1) 1e:00.1 Audio device: NVIDIA Corporation AD102 High Definition Audio Controller (rev a1) 22:00.0 VGA compatible controller: NVIDIA Corporation AD102 [GeForce RTX 4090] (rev a1) 22:00.1 Audio device: NVIDIA Corporation AD102 High Definition Audio Controller (rev a1) 23:00.0 VGA compatible controller: NVIDIA Corporation AD102 [GeForce RTX 4090] (rev a1) 23:00.1 Audio device: NVIDIA Corporation AD102 High Definition Audio Controller (rev a1) 4f:00.0 VGA compatible controller: NVIDIA Corporation AD102 [GeForce RTX 4090] (rev a1) 4f:00.1 Audio device: NVIDIA Corporation AD102 High Definition Audio Controller (rev a1) 52:00.0 VGA compatible controller: NVIDIA Corporation AD102 [GeForce RTX 4090] (rev a1) 52:00.1 Audio device: NVIDIA Corporation AD102 High Definition Audio Controller (rev a1) 56:00.0 VGA compatible controller: NVIDIA Corporation AD102 [GeForce RTX 4090] (rev a1) 56:00.1 Audio device: NVIDIA Corporation AD102 High Definition Audio Controller (rev a1) 57:00.0 VGA compatible controller: NVIDIA Corporation AD102 [GeForce RTX 4090] (rev a1) 57:00.1 Audio device: NVIDIA Corporation AD102 High Definition Audio Controller (rev a1)
禁用 nouveau ,它是第三方为 NVIDIA 显卡开发的驱动,没得到官方的认可:
1 2 3 4 $ cat > /etc/modprobe.d/blacklist-nouveau.conf << EOF blacklist nouveau options nouveau modeset=0 EOF
关闭包更新,否则可能会出现和我同事一样,安装好驱动后,被自动更新了一些包,导致 cuda toolkit 无法使用的情况:
1 sed -ri '/Update-Package-Lists/s#1#0#' /etc/apt/apt.conf.d/10periodic
文件 /etc/apt/apt.conf.d/50unattended-upgrades 里是在系统自动升级过程中,不更新的列表,例如有:
1 2 3 4 Unattended-Upgrade::Package-Blacklist { // The following matches all packages starting with linux- // "linux-"; ...
把 linux- 前面的 // 取消了,因为闭源显卡驱动和内核版本挂钩的,我们不希望升级 linux-image-* 和 linux-headers-*:
1 sed -ri '\@^//\s+"linux-"@s#^//##' /etc/apt/apt.conf.d/50unattended-upgrades
更新 initramfs 并重启
1 2 3 4 5 6 7 8 9 10 11 # apt 系列系统 update-initramfs -u # centos 系统 mv /boot/initramfs-$(uname -r).img{,.bak} dracut /boot/initramfs-$(uname -r).img $(uname -r) 重启 reboot # 记得验证不包含 nouveau lsmod | grep nouveau
安装驱动 不使用 apt 安装
从上面面俩文档(主要是第二个文档)的表格得到信息:
R470
R535
R550
Branch Designation
Long Term Support Branch
Long Term Support Branch
Production Branch
EOL 时间
July 2024
June 2026
February 2025
最小 CUDA 版本支持
CUDA 11.0+
CUDA 12.0+
CUDA 12.0+
所以驱动首选 535 , 官网驱动搜索页面 ,我这里选的非笔记本 4090 点击 search 选择后选择 535 下载,其他卡根据选项选择,例如下面:
GeForce RTX 4090: Type=GeForce Series=GeForce RTX 40 Series NVIDIA GeForce RTX 4090
A10: Type=Data Center / Tesla Series=A-Series NVIDIA A10
1 2 3 4 5 6 7 8 9 10 11 12 wget https://us.download.nvidia.com/tesla/535.161.08/NVIDIA-Linux-x86_64-535.161.08.run chmod a+x NVIDIA-Linux-x86_64-535.161.08.run # 确保有 gcc 和 linux-kernel-headers 和一些依赖 apt install -y \ gcc linux-kernel-headers \ pkg-config libvulkan1 ./NVIDIA-Linux-x86_64-535.161.08.run # 安装日志在 /var/log/nvidia-installer.log reboot
apt 安装方式 参考 ubuntu 官方文档 nvidia-drivers-installation
1 2 apt update apt install -y ubuntu-drivers-common
然后按照官方文档来,而且会添加一个 nvidia-detector 命令,执行会推荐你安装的版本。
查看显卡驱动信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 $ nvidia-smi Mon Apr 8 18:48:39 2024 +---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.113.01 Driver Version: 535.113.01 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 NVIDIA GeForce RTX 4090 Off | 00000000:1B:00.0 Off | Off | | 31% 25C P8 12W / 450W | 6112MiB / 24564MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ | 1 NVIDIA GeForce RTX 4090 Off | 00000000:1E:00.0 Off | Off | | 31% 26C P8 6W / 450W | 17876MiB / 24564MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ | 2 NVIDIA GeForce RTX 4090 Off | 00000000:22:00.0 Off | Off | | 30% 28C P8 15W / 450W | 4248MiB / 24564MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ | 3 NVIDIA GeForce RTX 4090 Off | 00000000:23:00.0 Off | Off | | 31% 28C P8 5W / 450W | 4246MiB / 24564MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ | 4 NVIDIA GeForce RTX 4090 Off | 00000000:4F:00.0 Off | Off | | 31% 25C P8 16W / 450W | 4246MiB / 24564MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ | 5 NVIDIA GeForce RTX 4090 Off | 00000000:52:00.0 Off | Off | | 30% 26C P8 12W / 450W | 4246MiB / 24564MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ | 6 NVIDIA GeForce RTX 4090 Off | 00000000:56:00.0 Off | Off | | 30% 27C P8 5W / 450W | 21974MiB / 24564MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ | 7 NVIDIA GeForce RTX 4090 Off | 00000000:57:00.0 Off | Off | | 31% 28C P8 12W / 450W | 16220MiB / 24564MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ # 这个路径也可以查看驱动,可以做一些脚本判断逻辑 $ cat /proc/driver/nvidia/version NVRM version: NVIDIA UNIX x86_64 Kernel Module 535.113.01 Tue Sep 12 19:41:24 UTC 2023 GCC version: gcc version 9.3.0 (Ubuntu 9.3.0-17ubuntu1~20.04)
右上角的 cuda version 是 cuda user-mode driver的版本,它是跟随 driver 安装的,和 cuda toolkit 没强关联,而后续开发使用到的 cuda toolkit 版本可以自己查看 nvcc -V
宿主机上有需求可以自行安装下,可能未来这块会更新加上安装步骤
安装 ctk 截至 2024/04/08 ,nvidia-container-runtime 已经废弃了,现在叫 nvidia-container-toolkit 并且官方文档切到下面:
官方安装文档
按照官方文档添加源后安装 nvidia-container-toolkit,会附带安装了三个包,四个包的信息为:
文件列表
说明
libnvidia-container1so 动态链接库,c 和 go 的 so 文件
例如给下面的二进制使用,下面依赖它,更新它可以向前兼容
libnvidia-container-tools/usr/bin/nvidia-container-cli
nvidia-container-toolkit-basenvidia-container-runtime 之前包名 runtime 二进制和它的配置文件 nvidia-ctk NVIDIA Container Toolkit 工具,它的 runtime 可以子命令可以代替人为编辑 container runtime 的配置文件
nvidia-container-toolkitnvidia-container-runtime-hook 二进制
依赖关系如下,version 是指 NVIDIA Container Toolkit 版本:
1 2 3 4 5 6 7 ├─ nvidia-container-toolkit (version) │ ├─ libnvidia-container-tools (>= version) │ └─ nvidia-container-toolkit-base (version) │ ├─ libnvidia-container-tools (version) │ └─ libnvidia-container1 (>= version) └─ libnvidia-container1 (version)
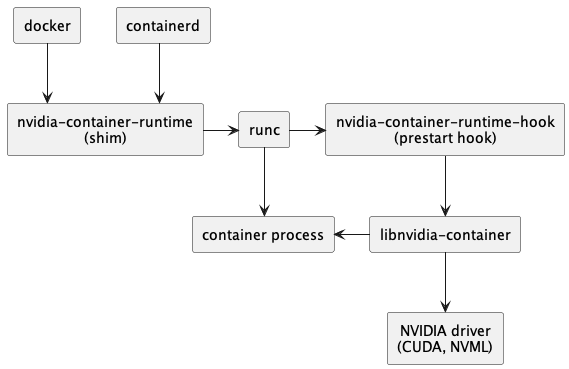
例如下面是官方文档的图,它是如何和 docker 工作的,点击图片也可以跳转上面包介绍信息:
点击展开 ubuntu22.04 上 deb 包内文件内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 $ dpkg -L libnvidia-container1 /. /usr /usr/lib /usr/lib/x86_64-linux-gnu /usr/lib/x86_64-linux-gnu/libnvidia-container-go.so.1.13.5 /usr/lib/x86_64-linux-gnu/libnvidia-container.so.1.13.5 /usr/share /usr/share/doc /usr/share/doc/libnvidia-container1 /usr/share/doc/libnvidia-container1/changelog.Debian.gz /usr/share/doc/libnvidia-container1/copyright /usr/share/lintian /usr/share/lintian/overrides /usr/share/lintian/overrides/libnvidia-container1 /usr/lib/x86_64-linux-gnu/libnvidia-container-go.so.1 /usr/lib/x86_64-linux-gnu/libnvidia-container.so.1 $ dpkg -L libnvidia-container-tools /. /usr /usr/bin /usr/bin/nvidia-container-cli /usr/share /usr/share/doc /usr/share/doc/libnvidia-container-tools /usr/share/doc/libnvidia-container-tools/changelog.Debian.gz /usr/share/doc/libnvidia-container-tools/copyright /usr/share/lintian /usr/share/lintian/overrides /usr/share/lintian/overrides/libnvidia-container-tools $ dpkg -L nvidia-container-toolkit-base /. /etc /etc/nvidia-container-runtime /etc/nvidia-container-runtime/config.toml /usr /usr/bin /usr/bin/nvidia-container-runtime /usr/bin/nvidia-ctk /usr/share /usr/share/doc /usr/share/doc/nvidia-container-toolkit-base /usr/share/doc/nvidia-container-toolkit-base/changelog.Debian.gz /usr/share/doc/nvidia-container-toolkit-base/copyright $ dpkg -L nvidia-container-toolkit /. /usr /usr/bin /usr/bin/nvidia-container-runtime-hook /usr/share /usr/share/doc /usr/share/doc/nvidia-container-toolkit /usr/share/doc/nvidia-container-toolkit/changelog.Debian.gz /usr/share/doc/nvidia-container-toolkit/copyright /usr/share/lintian /usr/share/lintian/overrides /usr/share/lintian/overrides/nvidia-container-toolkit
点击展开 centos 7.9 上 rpm 包内文件内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 $ rpm -ql libnvidia-container1 /usr/lib64/libnvidia-container-go.so.1 /usr/lib64/libnvidia-container-go.so.1.15.0 /usr/lib64/libnvidia-container.so.1 /usr/lib64/libnvidia-container.so.1.15.0 /usr/share/licenses/libnvidia-container-1.15.0 /usr/share/licenses/libnvidia-container-1.15.0/COPYING /usr/share/licenses/libnvidia-container-1.15.0/COPYING.LESSER /usr/share/licenses/libnvidia-container-1.15.0/LICENSE /usr/share/licenses/libnvidia-container-1.15.0/NOTICE $ rpm -ql libnvidia-container-tools /usr/bin/nvidia-container-cli /usr/share/licenses/libnvidia-container-1.15.0 /usr/share/licenses/libnvidia-container-1.15.0/COPYING /usr/share/licenses/libnvidia-container-1.15.0/COPYING.LESSER /usr/share/licenses/libnvidia-container-1.15.0/LICENSE /usr/share/licenses/libnvidia-container-1.15.0/NOTICE $ rpm -ql nvidia-container-toolkit-base /usr/bin/nvidia-container-runtime /usr/bin/nvidia-ctk /usr/share/licenses/nvidia-container-toolkit-base-1.15.0~rc.4 /usr/share/licenses/nvidia-container-toolkit-base-1.15.0~rc.4/LICENSE $ rpm -ql nvidia-container-toolkit /usr/bin/nvidia-container-runtime-hook /usr/share/licenses/nvidia-container-toolkit-1.15.0~rc.4 /usr/share/licenses/nvidia-container-toolkit-1.15.0~rc.4/LICENSE
离线的源和 deb 包下载都在下面链接上https://github.com/NVIDIA/libnvidia-container/tree/gh-pages
配置 runtime 增加 runtime 并设置为默认的 runtime
使用 nvidia-ctk 配置 官方推荐命令配置:
1 2 3 4 5 # docker nvidia-ctk runtime configure --runtime=docker --config=/etc/docker/daemon.json # containerd nvidia-ctk runtime configure --runtime=containerd
手动配置 主要是追加 runtime 和配置成默认的 runtime
docker vi /etc/docker/daemon.json 文件追加:
1 2 3 4 5 6 7 "default-runtime": "nvidia", "runtimes": { "nvidia": { "path": "/usr/bin/nvidia-container-runtime", "runtimeArgs": [] } },
containerd vim /etc/containerd/config.toml 在与 plugins."io.containerd.grpc.v1.cri".containerd.runtimes 中添加::
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia] privileged_without_host_devices = false runtime_engine = "" runtime_root = "" runtime_type = "io.containerd.runc.v2" [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options] BinaryName = "/usr/bin/nvidia-container-runtime" CriuImagePath = "" CriuPath = "" CriuWorkPath = "" IoGid = 0 IoUid = 0 NoNewKeyring = false NoPivotRoot = false Root = "" ShimCgroup = "" SystemdCgroup = true
将默认的 runtime 设置为 nvidia
1 2 [plugins."io.containerd.grpc.v1.cri".containerd] default_runtime_name = "nvidia"
需要重启 docker 或者 containerd
1 2 systemctl restart docker systemctl restart containerd
验证 1 2 docker run --rm --gpus all nvidia/cuda:12.4.0-base-ubuntu22.04 nvidia-smi nerdctl run --rm --gpus all nvidia/cuda:12.4.0-base-ubuntu22.04 nvidia-smi
镜像 tag 信息格式为 cuda 版本-base/runtime/devel-os,cuda 驱动版本可以 nvidia-smi 查看右上角
base: 包含 CUDA runtime (cudart)
runtime: FROM base 添加 CUDA math libraries 、 NCC 和 cuDNN
devel: FROM runtime 添加 headers development tools
镜像更多信息都查看 nvidia/cuda
一些信息,当 runtime 为 nvidia 时候,有变量和没变量,在 glibc 的容器内,会新增下面命令:
1 2 3 4 5 6 7 8 $ docker run --rm ubuntu sh -c 'ls -l /usr/bin/nvidia*' ls: cannot access '/usr/bin/nvidia*': No such file or directory $ docker run --runtime=nvidia -e NVIDIA_VISIBLE_DEVICES=all --rm ubuntu sh -c 'ls -l /usr/bin/nvidia*' -rwxr-xr-x 1 root root 54208 Sep 29 2023 /usr/bin/nvidia-cuda-mps-control -rwxr-xr-x 1 root root 18664 Sep 29 2023 /usr/bin/nvidia-cuda-mps-server -rwxr-xr-x 1 root root 142064 Sep 29 2023 /usr/bin/nvidia-debugdump -rwxr-xr-x 1 root root 208352 Sep 29 2023 /usr/bin/nvidia-persistenced -rwxr-xr-x 1 root root 678160 Sep 29 2023 /usr/bin/nvidia-smi
上面相关是代码实现的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func NewDriverBinariesDiscoverer (logger logger.Interface, driverRoot string ) return discover.NewMounts( logger, lookup.NewExecutableLocator(logger, driverRoot), driverRoot, []string { "nvidia-smi" , "nvidia-debugdump" , "nvidia-persistenced" , "nvidia-cuda-mps-control" , "nvidia-cuda-mps-server" , }, ) }
docker 特殊 docker 使用显卡,必须查看文档 docker-specialized
k8s 上使用 k8s 需要部署 NVIDIA 的 device plugin ,会 daemonset 起一个服务挂载宿主机 /var/lib/kubelet/device-plugins/ 目录,然后在目录下生成 socket 文件,kubelet 和这个 socket 文件按照 device plugin 要求 grpc 调用,部署去看官方的 github 部署。
部署后,可以 describe node 查看到信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Capacity: ... nvidia.com/gpu: 8 ... Allocatable: ... nvidia.com/gpu: 8 ... ... Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ nvidia.com/gpu 0 0
可以 kubectl describe node xxx -v=8 查看请求的啥接口,然后用 go-client 获取节点的 cpu 分配情况,如果不是 k8s ,可以参考 NVIDIA/k8s-device-plugin 里找下 go 的库来看节点 gpu 分配情况。cuda-sample 部署测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 cat << EOF | kubectl create -f - apiVersion: v1 kind: Pod metadata: name: gpu-demo-vectoradd spec: restartPolicy: Never containers: - name: vectoradd image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2 command: - bash - -c args: - | /tmp/vectorAdd nvidia-smi -L resources: limits: nvidia.com/gpu: 1 EOF
1 2 3 4 5 6 7 8 9 10 $ kubectl get pod -o wide | grep gpu gpu-demo-vectoradd 0/1 Completed 0 117s 1xx.xx.1.192 xx.7.xx.201 <none> <none> $ kubectl logs gpu-demo-vectoradd [Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done GPU 0: NVIDIA GeForce RTX 4090 (UUID: GPU-xxx-e0bf-xxx-60d4-xxxxxxx)
docker 和 cri-dockerd 的一些问题 查看文档 docker-specialized 实验发现一个问题,不带 --gpus all 或者 -e NVIDIA_VISIBLE_DEVICES=all 默认就能看到所有卡:
1 2 3 $ docker run --rm --gpus all nvidia/cuda:12.4.0-base-ubuntu22.04 nvidia-smi -L $ docker run --rm nvidia/cuda:12.4.0-base-ubuntu22.04 nvidia-smi -L $ docker run --rm --runtime=nvidia -e NVIDIA_VISIBLE_DEVICES=all nvidia/cuda:12.4.0-base-ubuntu22.04 nvidia-smi -L
这是因为 nvidia 成为默认的 runtime 了,然后 cuda docker 镜像都带了 ENV NVIDIA_VISIBLE_DEVICES=all 的环境变量,就是说上面三个是一样的。"default-runtime": "nvidia", 必须显式调用,就像下面:
1 $ docker run --rm --runtime nvidia --gpus all nvidia/cuda:12.4.0-base-ubuntu22.04 nvidia-smi
docker-compose v2 golang版本的话:
1 2 3 4 services: app: image: xxx runtime: nvidia
k8s 指定 runtime 必须先创建一个 RuntimeClass 对象
1 2 3 4 5 apiVersion: node.k8s.io/v1 kind: RuntimeClass metadata: name: nvidia handler: nvidia
然后
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 cat << EOF | kubectl create -f - apiVersion: v1 kind: Pod metadata: name: gpu-demo-vectoradd spec: restartPolicy: Never runtimeClassName: nvidia # <- 这里 containers: - name: vectoradd image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2 command: - bash - -c args: - | /tmp/vectorAdd nvidia-smi -L resources: limits: nvidia.com/gpu: 1 EOF
理想是美好的,但是在一个干净环境上按照步骤实际发现,RuntimeClass.handler=nvidia 在 cri-dockerd 环境下 pod 无法创建 sandbox,发现它改为 docker 才行,但是这样下 nvidia-device-plugin 指不指定 runtimeClassName 都找不到卡,日志:
1 2 3 4 5 6 7 8 9 10 I0412 10:31:24.585290 1 main.go:256] Retreiving plugins. W0412 10:31:24.585562 1 factory.go:31] No valid resources detected, creating a null CDI handler I0412 10:31:24.585597 1 factory.go:107] Detected non-NVML platform: could not load NVML library: libnvidia-ml.so.1: cannot open shared object file: No such file or directory I0412 10:31:24.585622 1 factory.go:107] Detected non-Tegra platform: /sys/devices/soc0/family file not found E0412 10:31:24.585629 1 factory.go:115] Incompatible platform detected E0412 10:31:24.585631 1 factory.go:116] If this is a GPU node, did you configure the NVIDIA Container Toolkit? E0412 10:31:24.585634 1 factory.go:117] You can check the prerequisites at: https://github.com/NVIDIA/k8s-device-plugin#prerequisites E0412 10:31:24.585637 1 factory.go:118] You can learn how to set the runtime at: https://github.com/NVIDIA/k8s-device-plugin#quick-start E0412 10:31:24.585640 1 factory.go:119] If this is not a GPU node, you should set up a toleration or nodeSelector to only deploy this plugin on GPU nodes I0412 10:31:24.585644 1 main.go:287] No devices found. Waiting indefinitely.
正常日志是:
1 2 3 4 5 6 I0408 10:40:23.126999 1 main.go:256] Retreiving plugins. I0408 10:40:23.128195 1 factory.go:107] Detected NVML platform: found NVML library I0408 10:40:23.128311 1 factory.go:107] Detected non-Tegra platform: /sys/devices/soc0/family file not found I0408 10:40:23.197946 1 server.go:165] Starting GRPC server for 'nvidia.com/gpu' I0408 10:40:23.199739 1 server.go:117] Starting to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock I0408 10:40:23.212600 1 server.go:125] Registered device plugin for 'nvidia.com/gpu' with Kubelet
最后排查出发现容器的 Runtime 不对:
1 2 $ docker inspect be4d | grep -i runtime "Runtime": "runc",
试了下 docker run --runtime nvidia 是能工作的, kubelet 肯定会把 handler 传递到 CRI runtime 的,也就是 cri-dockerd 上,唯一可能性是 cri-dockerd 没配置 Runtime 传递到 docker 的 create 阶段,最后调试了下发现果然是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 > github.com/Mirantis/cri-dockerd/core.(*dockerService).CreateContainer() ./core/container_create.go:137 (hits goroutine(36839):1 total:1) (PC: 0x229e164) 132: cleanupInfo, err := ds.applyPlatformSpecificDockerConfig(r, &createConfig) 133: if err != nil { 134: return nil, err 135: } 136: => 137: createResp, createErr := ds.client.CreateContainer(createConfig) 138: if createErr != nil { 139: createResp, createErr = recoverFromCreationConflictIfNeeded( 140: ds.client, 141: createConfig, 142: createErr, (dlv) p createConfig github.com/docker/docker/api/types.ContainerCreateConfig { Name: "k8s_nvidia-device-plugin-ctr_nvidia-device-plugin-daemonset-5tm6...+52 more", Config: *github.com/docker/docker/api/types/container.Config { ... HostConfig: *github.com/docker/docker/api/types/container.HostConfig { Binds: []string len: 4, cap: 4, [ "/var/lib/kubelet/device-plugins:/var/lib/kubelet/device-plugins", "/data/kube/kubelet/pods/59f9fe0c-4397-4a83-a149-97ed696d4551/vol...+99 more", "/data/kube/kubelet/pods/59f9fe0c-4397-4a83-a149-97ed696d4551/etc...+17 more", "/data/kube/kubelet/pods/59f9fe0c-4397-4a83-a149-97ed696d4551/con...+62 more", ], ContainerIDFile: "", LogConfig: (*"github.com/docker/docker/api/types/container.LogConfig")(0xc001505228), NetworkMode: "container:8d3c044a8c0339faed520efebe9dc199937de3515eb9a3baf723ed...+10 more", PortBindings: github.com/docker/go-connections/nat.PortMap nil, RestartPolicy: (*"github.com/docker/docker/api/types/container.RestartPolicy")(0xc001505258), AutoRemove: false, VolumeDriver: "", VolumesFrom: []string len: 0, cap: 0, nil, ConsoleSize: [2]uint [0,0], Annotations: map[string]string nil, CapAdd: github.com/docker/docker/api/types/strslice.StrSlice len: 0, cap: 0, nil, CapDrop: github.com/docker/docker/api/types/strslice.StrSlice len: 1, cap: 1, ["ALL"], CgroupnsMode: "", DNS: []string len: 0, cap: 0, nil, DNSOptions: []string len: 0, cap: 0, nil, DNSSearch: []string len: 0, cap: 0, nil, ExtraHosts: []string len: 0, cap: 0, nil, GroupAdd: []string len: 0, cap: 0, nil, IpcMode: "container:8d3c044a8c0339faed520efebe9dc199937de3515eb9a3baf723ed...+10 more", Cgroup: "", Links: []string len: 0, cap: 0, nil, OomScoreAdj: -997, PidMode: "", Privileged: false, PublishAllPorts: false, ReadonlyRootfs: false, SecurityOpt: []string len: 2, cap: 2, [ "no-new-privileges", "seccomp=unconfined", ], StorageOpt: map[string]string nil, Tmpfs: map[string]string nil, UTSMode: "", UsernsMode: "", ShmSize: 0, Sysctls: map[string]string nil, Runtime: "", Isolation: "", Resources: (*"github.com/docker/docker/api/types/container.Resources")(0xc001505440), Mounts: []github.com/docker/docker/api/types/mount.Mount len: 0, cap: 0, nil, MaskedPaths: []string len: 10, cap: 16, [
可以看到上面倒数第 11 行,是为空的,上层的调用链里,只允许 RuntimeHandler不为空情况下设置为 docker:
1 2 3 4 if r.GetRuntimeHandler() != "" && r.GetRuntimeHandler() != runtimeName { return nil , fmt.Errorf("RuntimeHandler %q not supported" , r.GetRuntimeHandler()) }
后面的调用链里也没去使用 r.GetRuntimeHandler() 或者设置 x.HostConfig.Runtime ,意味着不配置 RuntimeClass.handler 或者设置为 docker 都是使用 docker 默认的 runtime。
然后我修改代码编译后才发现可以使用 RuntimeClass.handler=nvidia 了,并且 pod 的容器的 runtime 也正常了,向 cri-dockerd 提了 pr support RuntimeClass.handler
参考