
记录下一次虚拟机上K8S IM 服务高峰期 timeout 排查过程。
由来
客户采购我们服务,客户提供了 arm64 鲲鹏虚拟化上的 Kylin 虚机部署,整体是部署 K8S 后再部署 IM 业务,今年2月份开始,IM 服务在白天高峰期使用期间频繁消息发不出去,日志里频繁出现 grpc 报错 connenction timed out
环境信息
k8s:
- version:
1.27.16 - CNI: flannel vxlan
- Pod CIDR:
10.187.0.0/16
docker: 26.1.4
os:Kylin Linux Advanced Server V10 (Tercek)
kernel:4.19.90-23.50.v2101.ky10.aarch64
客户环境完全内网,无法远程,不允许执行 sudo 和切到 root,需要执行啥 root 命令和抓包都要输出相关步骤给客户,客户反馈给他们的云平台的人执行。
故障现象描述
客户去年采购我们服务,然后客户公司的云平台提供了 arm64 鲲鹏虚拟化上的 Kylin 虚机,然后我们实施去部署 IM 服务,今年2月份开始,IM 服务在白天高峰期使用期间频繁消息发不出去,就是类似微信那样消息发送失败,然后消息左侧有个红色圈,点它重试发送,或者消息转圈很久才发送出去。
客户反馈去年没这个现象,今年2月份中附近开始频繁出现,已经严重影响使用,使用人数没有增加,为啥开始频繁出现。
出差排查
安排我和一个 IM 服务研发出差去客户现场排查,总体大致人群:
- 我司人员有 3-4 人在现场,我和 IM 研发为主
- 客户的 pm 和部分技术人员
- 客户的云平台人员
离谱的后端接口逻辑
第一天 03/27 周五晚上到达,然后去客户那儿,其他同事认为是我们以前设计的 raw 规则问题导致,来之前给了客户删除相关规则的命令,客户的云平台人员执行变更后,让我去客户环境确认下,客户晚上是不使用 IM 服务的。确认 IM 几台删除了相关 raw 规则,然后去客户办公室打算走,然后客户有个女 nodejs 后端上架一个插件后功能有问题,就大致帮她看了下。
页面功能大概为打开投稿弹出一个上传,封面图片和 pdf 和其他日期参数,然后提交后显示已有的,显示不到,去数据库查询,pdf 和图片相关信息都为空。坐在旁边看了下代码,代码逻辑大概如下:
1 | let pdf_name=""; |
大概伪代码如上,因为 pdf 和封面上传,最后提交表单创建,她写的一个上传接口支持 pdf 和封面两种类型,最后提交的时候取全局变量入库,问我能不能只改后端解决问题(前后端需要打包成一个插件包部署的),我想了下只有前后端一起改才能解决了,最主要的是前端居然也会配合这种逻辑来写。
最后让她们前后端都重构,分为三个接口做,图片和 pdf 和最后提交(一个上传和一个提交也行,但是怕她们后续还要做修改已有投稿属性需求),改的过程中发现前端居然用的是原生 js ,还有原型链到处用,改错了好几次,问怎么不用 ts 强类型的,她回复项目一直用的 js,最后折腾好久才上线。
当然我中途说了上传文件逻辑存在隐患,文件名都是原始的返回前端,会可以被人恶意攻击覆盖,不过她们也不管了,说先上线。
初步排查
03/30 IM 研发到场,结果前一周五晚上下班后还做了另一个变更,客户上了另一个他们开发的插件,该插件造成 IM 服务某个地方有问题,当天基本花时间处理这个问题去了。
IM 研发组在出差之前让现场根据他们代码逻辑搜了下日志,找到了 grpc 的报错:
1 | // https://github.com/grpc/grpc-go/blob/v1.60.1/internal/transport/http2_client.go#L1571 |
是服务调用 grpc read 报错了 error reading from server: read tcp 10.187.6.94:54034 -> 10.187.9.85:3169: read: connection timed out,从 grpc 逻辑看,这个不是 grpc 应用层,而是下层网络层出现的问题。
后面搜关键字 error reading from server 发现 IM 服务涉及到作为 grpc 客户端的服务都会白天业务高峰期随机打这个报错,根据 trace-id 搜索日志,发现服务日志上下文出现了以下:
- 作为 http
i/o timeout的Post \"http://....\": dial tcp 10.96.x.x:80 i/o timeout - 作为 redis 客户端的
read tcp 10.187.x.xx:43823 -> host_ip:6379: i/o timeout
查看 Prometheus 监控均无丢包:
1 | # 两天跨度 |
并且监控上看 conntrack 条目都没达到 max,系统日志 kernel 和 dmesg 均无异常。
现场服务分布是 IM 服务在其中的八台节点上面,然后让客户找 3-4 台迁移到同一个虚拟化宿的主机上,客户说不支持,客户说问了云平台说不支持。我算是看出来了,让这个云平台做事非常麻烦😂。
抓包
由于客户云平台不愿意调整节点虚机分布情况,必须有作为,03/31 号就想着抓下包看看,客户云平台要求我们发抓包命令他们去抓😂,哎心累。选择一个最频繁的 IM 服务,抓它作为 grpc 客户端访问另一个 IM 服务的情况:
1 | timeout 15m tcpdump -nn -i cni0 host and 10.187.5.89 and port 3169 -w 21.41-10.187.5.89-port3169.pcap |
因为 K8S 的 Pod 容器的 veth 都是挂在 cni0 下的,所以抓 cni0 和限制端口,3169 是另一个服务的 grpc server 端口。抓完后,搜这个 5.89 的 grpc client 容器日志 error reading from server 找它作为客户端时候端口数字,然后抓包文件在 wireshark 里过滤,最后找到了对应的:
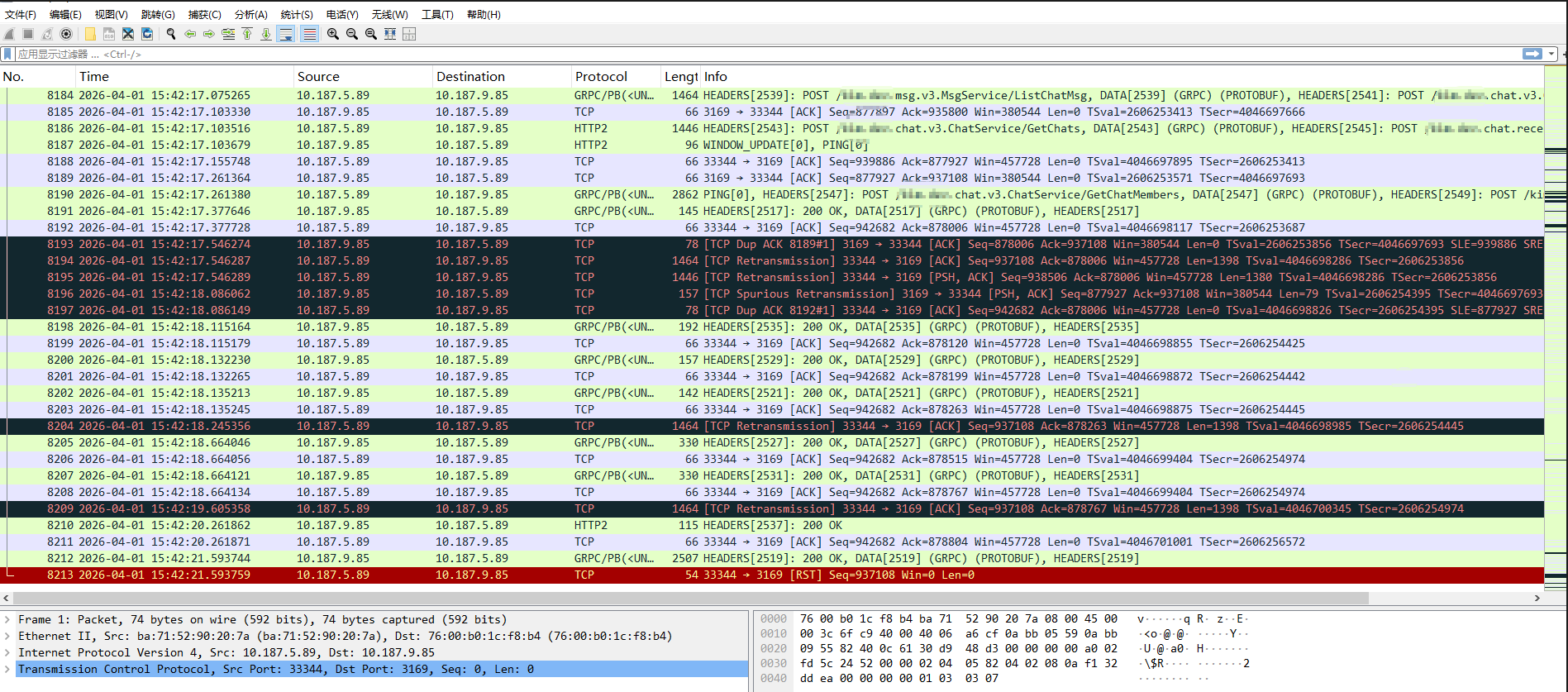
过滤后的 pcap 文件使用 tcpdump 转换下
1 | tcpdump -nn -r xxx.pcap > grpc.txt |
可以看到 sack hole ack 937108 sack {939886:942682} 说服务端收到了后面的 939886:942682,但还在等前面的 937108:939886。由于监控查看了网卡没有丢包 drop,可能发生在队列、qdisc、conntrack、overlay、虚拟网卡、软中断、对端内核处理慢、中间 NAT/SLB 等位置。
期间客户不愿意迁移虚机,就让我们调整服务分布:
- grpc client 和 server 的 Pod 到同一个节点
- 相关 Pod 重启调整副本到其他节点上啥的
- 某个服务副本数量调整
让我们各种配合折腾,然后出现了某个他们认为不合理的现象,晚上开会让我们解释,服务太多了而且是网状调用,我感觉解释没啥意义。
进一步分析
在开会沟通的时候,客户有个人员反馈在白天业务高峰期长 ping 了下节点 IP 发现丢包,结合前面监控和都是 client 角色的 tcp 连接出现,而且 IM 节点机器都在同一个二层,感觉更像是软中断造成。当场离开会议室,去客户测试环境上用 iperf3 压测了下确实复现了。
然后第二天白天客户上班时间,查看了下节点监控,白天的时候业务高峰期 CPU 负载都普遍 70%-80%,使用 mpstat 看下:
1 | mpstat -P ALL 1 |
CPU9 的软中断太高了,网卡收包软中断可以通过 Linux 的 softnet_stat 查看:
1 | awk '{for (i=1; i<=NF; i++) printf strtonum("0x" $i) (i==NF?"\n":" ")}' /proc/net/softnet_stat | column -t |
结论
可以看到 cpu softirq 在 CPU9 上很高,而 /proc/net/softnet_stat 分析:
第二列(dropped)为0,softnet_stat 第三列(time_squeeze)里为不0:
• 每轮 softirq 有处理预算(时间/包数),内核规定一次软中断最多处理 netdev_budget 个包(默认 300),或最多运行 2 个 jiffies(约 2ms),没处理完就被调度器打断,下次再来
• 若时间 / 包数到了,队列里还有没处理完的包,就会 time_squeeze++
然后👆 /proc/interrupts 里看到 virtio3-input 在 CPU9 上中断太多了,而 virtio3 对应业务网卡 enp3s0, 说明 cpu 在处理网卡包的时候软中断太多。
不是:
• ❌ backlog 太小(否则 /proc/net/softnet_stat 第2列会涨),并且客户的 backlog 不是默认的 1000 而是 8000
• ❌ ring buffer 溢出(通常会伴随 drop)
• ❌ 纯网络丢包
从这些信息来看:
1 | 流量进入网卡 |

询问了下研发,发消息的 IM 大概调用链如下
graph TD
IM_C[IM 客户端]
IM_C --http--> GW[总网关]
GW[总网关] --http--> IM_G[IM 网关]
IM_G[IM 网关] --http--> IM_LOGIC[IM logic]
IM_LOGIC[IM logic] --grpc--> IM_MSG[IM MSG]
IM_MSG[IM MSG] --grpc--> IM_IDG[IM IDG]
为啥只有 grpc 报错,应该也有 http 的,然后 IM 服务研发告诉我 IM 服务的 http client 封装的有重试逻辑,然后在 loki 里搜 IM 服务的 retry 关键字搜了下确实也有不少。然后不筛选 IM 服务搜 http 的 Client.Timeout 发现也有其他业务组的超时。因为消息需要大量鉴权和判断用户组和权限啥的,所以 IM 服务都是用 grpc 长链接互相调用,避免多次 http 调用产生的开销,而长连接最容易收到影响,例如开头提到的 redis client 也报错了。
解决方案
单 CPU 处理网络 I/O 存在瓶颈下,可以使用网卡多队列提高性能。
通常情况下, 每张网卡有一个队列(queue), 所有收到的包从这个队列入, 内核从这个队列里取数据处理. 该队列其实是 ring buffer(环形队列), 内核如果取数据不及时, 则会存在丢包的情况.
一个CPU处理一个队列的数据, 这个叫中断。默认是cpu0(第一个CPU)处理。一旦流量特别大, 这个 CPU 负载很高, 性能存在瓶颈。所以网卡开发了多队列功能, 即一个网卡有多个队列, 收到的包根据 TCP 四元组信息 hash 后放入其中一个队列, 后面该链接的所有包都放入该队列。每个队列对应不同的中断, 使用 irqbalance 将不同的中断绑定到不同的核。充分利用了多核并行处理特性。提高了效率。
RSS
目前是单队列到单个 CPU 上,而 Linux 有 RSS 硬件层面解决
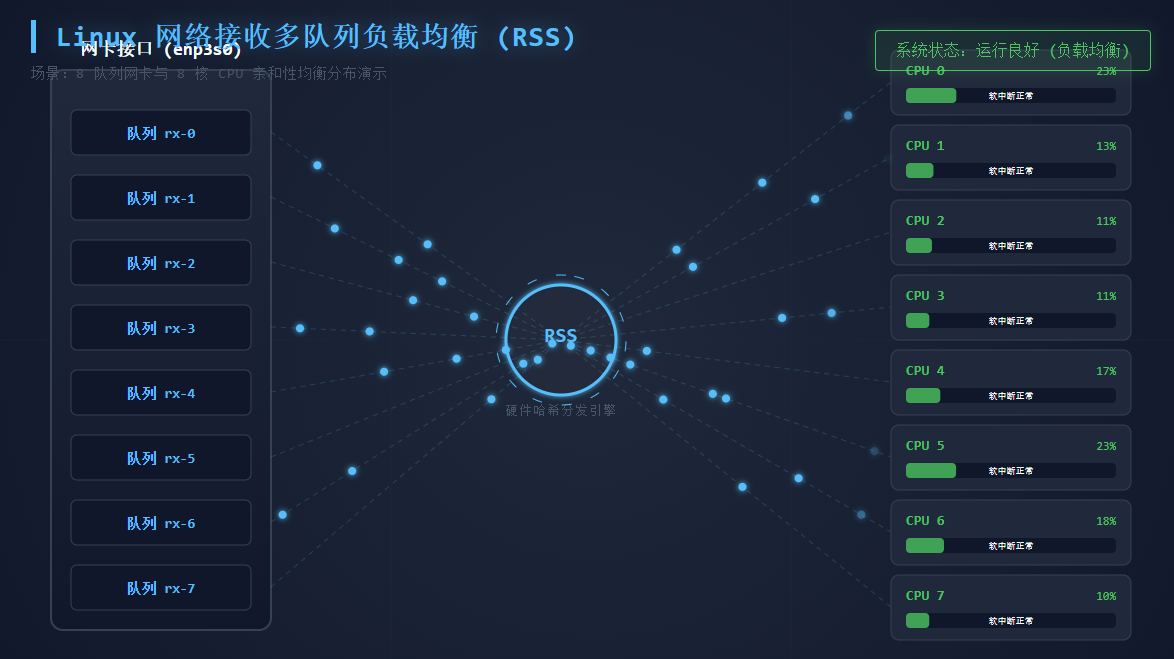
但是机器是虚拟机,网上很多网络优化文章都是物理机下使用的,ethtool -x eth0 啥的都无法使用或者信息缺少和不支持,需要虚拟化上调整 virsh xml:
1 | <model type='virtio'/> |
开启后会消耗主机更多的虚拟化域 CPU/内存资源,即与虚拟机共享主机上的 CPU/内存资源,单个虚拟机因网卡多队列导致额外的资源占用为:按1个虚拟机3个网卡来算,每个网卡8队列深度2048,会占用24个vhost线程,高负载极端情况下占用480MB内存(队列深度为2048,假设平均报文长度为10KB,则一个vhost-net线程最多因缓存报文占用20MB内存);空载情况下占用的内存消耗可以忽略。开启后可以虚机内通过:
1 | ethtool -l enp3s0 |
但是客户的虚拟化云平台组不让变更,说要是给虚拟化整崩了咋整。
RPS
然后就看系统层面有无解决办法,然后使用 Linux 的 RPS 了。RSS(工作在网卡的硬件层) 和 RPS(工作在 Linux 内核的软件层) 的目的都是把数据包分散到更多的 CPU 上进行处理,使得系统有更强的网络包处理能力。在把数据包分散到各个 CPU 时,保证了同一个数据流在一个 CPU 上,这样就可以减少包的乱序。
iperf3 压测复现,在客户的测试环境使用找4台机器:
1 | 机器1起两个server端口 |
iperf3 的 Lost/Total 列和压测期间ping统计信息都可以直观看到丢包,然后尝试配置:
1 | 调整 rps_cpus 为4个核心,f的二进制为1111代表4个核心,需要sudo或者root下执行 |
然后同样步骤 iperf3 压测发现 ping 都不会丢包,并且查看 cpu 软中断不会集中到一个核心上。
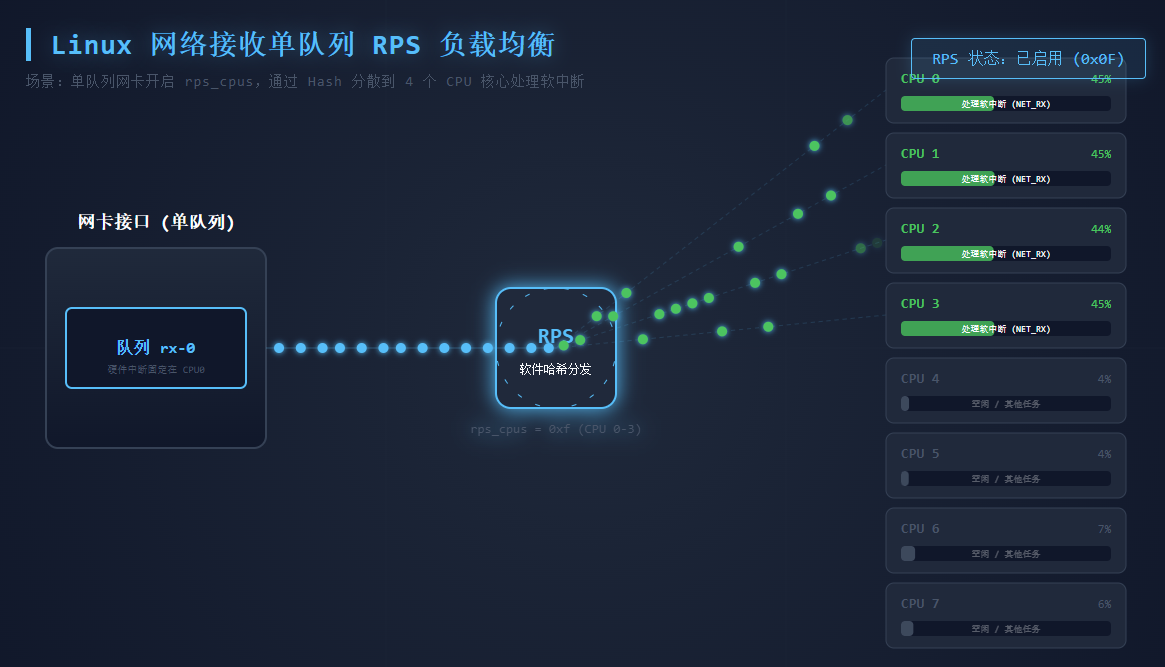
客户生产环境所有机器最小为 16C,所有机器的 rps_cpu 可以先配置4个核心不会太激进。其次客户是虚拟机,不是有 NUMA 的物理机,有 NUMA 给核心绑定的同时没有配置cpu亲和性的话会导致 cpu 跨 NUMA 而增加耗时,所以在虚拟机上这个方案没问题,客户问我虚拟化崩了咋整,我说调整虚拟机的内核参数给虚拟化整崩了那云平台那帮人不应该去找鲲鹏虚拟化的人理论吗。后面说这个变更要写方案和走流程审批。
持久化,上面是 echo,机器重启就无了,可以用 systemd:
1 | cat > /etc/systemd/system/set-rps.service << EOF |
但是怕别人给 systemd 这个 unit 禁止了,使用 udev:
1 | cat > /etc/udev/rules.d/99-rps.rules << EOF |
或者 NetworkManager dispatcher:
1 | cat > /etc/NetworkManager/dispatcher.d/rps << EOF |
对于 node_exporter 相关采集是没有开启的,需要调整下
1 | // https://github.com/prometheus/node_exporter/blob/v1.8.2/collector/interrupts_common.go#L31 |
同理还有 softirqs,发现 softnet 开启了,但是没做 grafana 指标。
反思
客户晚上 IM 服务无人使用,客户云平台的人一直不让先变更一两台,然后客户各种让我们调整服务副本数量和挪节点和重启服务和重启机器,每次操作完后的现象让我们解释和开会,非常心力憔悴,然后现场待到 04/03周五,客户心累了让开个大会拉了我领导和 IM 研发领导,让我们指派一个总对接人,这个对接人向他汇报,缺啥人对接人去找。然后办公室的同事会后又拉个会,明明我们写了现场排查记录的云文档,后面上会来的人不仔细看,就直接来问现场某些监控数据和命令输出和内核参数,又是重复的浪费时间。然后又说内部搭建环境复现,问题是当天周五又是清明节放假,我觉得不现实,首先内部 arm64 机器资源紧张,而且当天下午肯定很多人请假,到时候谁来搭建环境和压测复现,而且客户节点和配置规格又高,客户等不了这么久。
监控我们做了监控回放,但是客户监控数据很大,导出两天都很久,然后又是老版本,发到办公室的同事重放失败和慢,新版本又换了监控 agent 和指标。私有化就是这样,不像 toC 那样只有自己环境一个最新版本,很多客户现场是老版本而且不愿意升级。
内核参数这块我记得以前三四年前配合麒麟找一个问题原因,麒麟让执行某个命令是收集 /proc /sys 目录下每个文件打包成压缩包,但是同事找了下麒麟的最新对接人,他说没这种。我记得以前整过一次的,哎,算了。
由于 /proc /sys 下存在部分文件一直有内容产生的,直接 tar 打包成压缩包不现实,谷歌搜了下类似需求发现有 sos_report 命令,然后后面出差回来在华为云上开了按时计费的鲲鹏机器,发现 sos_report 会检查 os-release 直接报错不支持的系统,查看了下鲲鹏的相关参数:
1 | sysctl -a |& grep -E 'net.core. .mem_max|net.ipv4.udp_mem|net.core.netdev_build|rps_' |
开了一个 arm64 的 CentOS 还是啥系统来着,发现能收集到,但是解开看了下缺数据:
1 | /root/sosreport-ecs-3dda-2026-04-08-yhycnjr/sys/class/net/eth0 |
这次排查给我的感觉就像看病,一个病人觉得胸口不舒服,然后给他先开药吃下后续观察,他不吃,开检查说怕辐射,开穿刺病理检查说怕危险,啥都不愿意,就是要你最简单的排查手段能查出是啥病,这要不是 TOB和TOG 环境,而是 TOC 自己的环境,老早就晚上找时间调整下第二天就看成果了。